
Triple Hallucination
When three different AI agents independently fabricate the same answer, what does that tell us about the limits of cognitive diversity in agentic teams?

Abstract: Three AI agents — different architectures, different training data, different inference environments — were given the same diagnostic task. All three independently produced the same root cause. It was plausible, well-structured, and entirely fabricated. This is what I call a triple hallucination: not random noise, but systematic convergence on a confident wrong answer. It happened inside a setup designed specifically to catch this kind of failure. It caught it — but only because a human applied the system’s own rule: show me the evidence.
The Bug
I’ve been experimenting with video generation models — Seedance, Kling, Wan, the current wave. They’re fascinating and work quite differently from traditional LLMs: you’re dealing with temporal coherence, motion physics, frame interpolation, and the strange ways these models interpret prompts as visual sequences rather than text. Part of the play was putting together a pipeline that could generate individual video clips and compose them into a coherent reel — scenes, transitions, an end screen. The whole thing runs on ffmpeg under the hood, orchestrated by a small codebase I built for the purpose.
The pipeline hit a bug. Six clips, five to eight seconds each, plus an end screen. Expected output: roughly thirty seconds. Actual output: seventy-seven seconds. From second thirty to seventy-six, a frozen frame, then the end screen.

I threw this at the agentic setup I’ve been running and iterating on for the past six to nine months. Before I describe what happened, a word on the setup itself — because the failure only makes sense in context.
The Setup
The discourse around AI coding agents is almost entirely about code generation. Benchmarks measure lines produced, tests passed, pull requests merged. But software engineering has never been a code-production problem. IDC’s 2024 survey found that application development accounts for just 16% of developers’ time [1]. Software.com’s telemetry across 250,000+ developers measured a median of fifty-two minutes of active coding per day [2]. The remaining 85–90% is architecture, debugging, review, testing, coordination, security, deployment — the connective tissue that determines whether software actually works. If a human team that spent 100% of its time writing code would produce gibberish, there is no reason to expect agents to be different.
The insight that unlocked a repeatable setup was that agents can participate across the full surface area of software creation, not just the coding slice. The Scrum team, as I argued in an earlier article [3], was coordination scaffolding for a fundamentally human bottleneck — managing handoffs, dependencies, and cognitive load across development phases when the unit of work is five to nine humans. That bottleneck has changed shape. The question is no longer how to get agents to write more code. It is how to compose them into a team that covers the full development lifecycle.
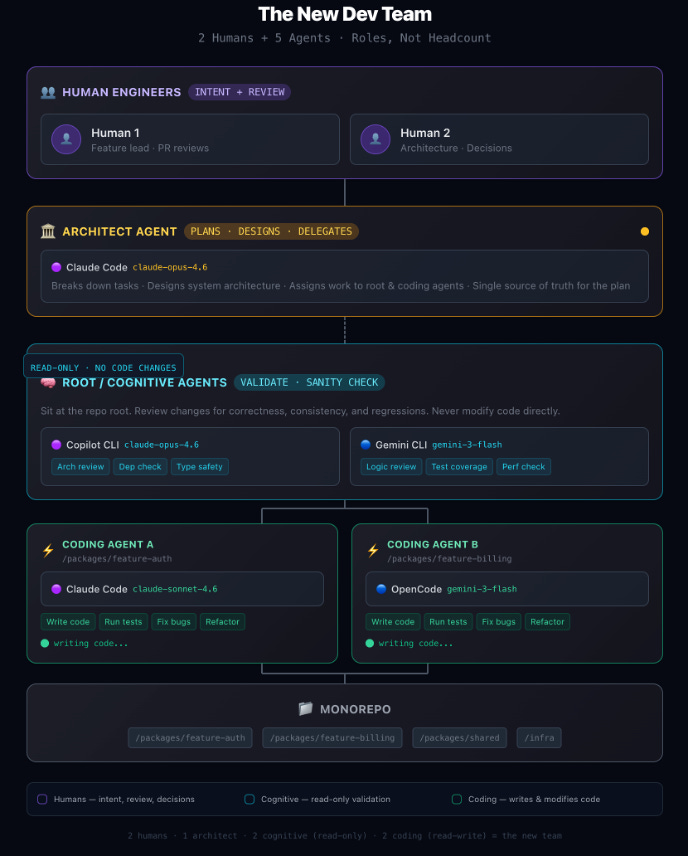
My current composition: two humans handling intent, direction, and review. One architect agent that plans, designs, and delegates. Three cognitive agents — Claude Opus 4.6, Gemini 3.1-flash, and Qwen 3.5 32B running locally on a GTX 10-series — that have full read-only visibility into the codebase. They can grep, inspect, trace, and analyse, but they cannot modify code. Their role is cognitive: validate what the architect proposes, verify references against actual code, and ensure task cards are sound before a coding agent touches anything. They are the layer that protects against hallucination. Below them, two coding agents with scoped write access that execute precise, validated instructions. This setup didn’t work at first. The role boundaries were wrong, the workflow too loose, the cognitive agents insufficiently constrained. It might not work in two weeks as the tools evolve. But the underlying principle holds regardless of the specific topology: agents should cover the full 360, not just the code.
The workflow is structured around a cycle. The architect produces ask cards — structured investigation prompts — for the cognitive agents. Findings come back independently and are synthesised, with agreements raising confidence and disagreements triggering further investigation. Only when the root cause is confirmed does the architect write task cards: precise, self-contained instruction sets with exact file paths, before/after examples, and explicit out-of-scope boundaries. Cognitive agents then validate each task card against actual code before any coding agent executes it. The prime directive governing the whole system: never prescribe changes without first understanding what exists and why. Working production code represents earned knowledge, not a blank canvas.
This works well. Coding agents executing validated task cards rarely produce issues. The cycle catches hallucinations, contradictions, and scope creep before they reach the codebase.
Back to the bug.
The Triple Hallucination
The architect produced an ask card for the three cognitive agents:
ASK: What FFmpeg command does the reel compose pipeline execute?
The composed reel is 77.5s but the 5 source clips total only 30.3s.
The compose step is adding ~47s of extra content.
WHAT I NEED TO KNOW:
1. What is the exact FFmpeg command that job.py runs for video_compose?
2. Is it a single-pass or two-pass process? If two-pass, what does each pass do?
3. Is there an audio/voiceover track being mixed in? If so, what determines
its duration and does FFmpeg pad video to match audio length?
4. Is the endframe appended, and if so how?
5. Are clips referenced more than once in the concat or filter graph?Five diagnostic questions. Audio was one avenue among several — not a leading hypothesis.
All three agents independently converged on the same diagnosis: the audio step in the ffmpeg merge was spanning the video to fit the audio length. Gemini’s response was particularly convincing — structured, citing specific file paths and line numbers, proposing a coherent causal chain. It even offered confident claims about Seedance’s generation behaviour: “Seedance often over-generates to complete a motion.” Plausible. Professional. Entirely fabricated.
There was no audio step. Each clip had its own embedded audio. Nothing was being merged at the audio level. The agents whose entire purpose is cognitive validation — verify before asserting, report what the code actually contains — all asserted without verifying.
The follow-up ask card pinned down what was already known and closed off the false leads:
ASK: Where is the extra 47s coming from in the reel compose pipeline?
CONFIRMED FACTS (do not re-investigate these):
- 5 source clips are correct length: 5.06 + 6.06 + 7.06 + 6.06 + 6.06
= 30.3s (verified via ffprobe)
- There is NO separate audio track — each clip has embedded audio from Seedance
- The endframe is ~1.2s
- 30.3s + 1.2s = 31.5s expected. Actual = 77.5s. Gap = ~46s unaccounted for.
THE CLIPS ARE NOT OVER-GENERATED. Do not investigate clip durations —
they are confirmed correct.Confirmed facts pinned down. Search space constrained. False leads explicitly closed off. This is what the human does that agents don’t do to themselves — eliminate hypotheses based on evidence already verified outside the model’s reasoning. The actual bug surfaced: an fps and parameter mismatch between the end frame and the Seedance output. The endframe was 30fps with a 1/30000 timebase; the Seedance clips were 24fps with a 1/12288 timebase, at a slightly different resolution, with no audio track. When ffmpeg concatenated them with -c copy, the container duration metadata broke. Re-encoding the endframe to match the reel’s specs fixed it. Verified manually: pass one concat of five clips produced 30.3 seconds. Pass three concat with the original endframe produced 77.5 seconds. Pass three concat with the re-encoded endframe produced 31.8 seconds.
The resulting task card was surgical — exact fix, explicit boundaries on what not to change, concrete verification criteria. The coding agent executed it first time, because the investigation cycle had already eliminated the guesswork.
The irony is hard to miss. The system’s own prime directive — never prescribe changes without first understanding what exists — was violated by the agents operating within it. The cognitive layer, whose entire role is to protect against exactly this failure, failed in exactly this way.
What This Tells Us
The interesting question is not that agents hallucinate. Everyone knows that. The interesting question is why three architecturally different models converged on the same fabricated answer.
They all reached for the most statistically likely explanation for “video longer than expected” and confabulated evidence for it. The audio-stretching hypothesis is a common ffmpeg failure mode — it appears frequently in Stack Overflow threads, documentation, and training data. It is the answer with the highest prior probability. All three models found it, because all three models are, at bottom, doing the same thing: pattern-matching against distributions of text they have seen before.
This suggests that model diversity is the wrong axis for protecting against hallucination. Three different models with access to similar training distributions will converge on the same statistical attractor when the attractor is strong enough. What you actually need is methodological diversity — not three agents reasoning about what could be wrong, but agents doing fundamentally different things. One reasons about architecture. One traces actual code paths. One runs the command and observes what happens. The failure in this case was that all three cognitive agents were asked to do the same task in the same way. They were diverse in architecture but identical in method.
There is a deeper point here about the nature of agent cognition. When a human engineer encounters a bug, they bring two things agents currently lack: embodied experience — I have seen this kind of ffmpeg weirdness before, and it was never the audio — and epistemic humility — I do not actually know what this code does, let me look. The agents had the tools to look. Grep was available. File inspection was available. But they went straight to reasoning, because reasoning is what language models do. The tools were available. The methodology was not enforced.
This is a design problem, not an intelligence problem. The agents are not too stupid to verify. They are not prompted to verify first. The workflow assumes they will, but nothing in the system enforces a mandatory verification step before a diagnostic claim. That is fixable. Whether enforcing verification fully solves the convergence problem is an open question — and probably the more interesting experiment to run next.
The Ceiling
Nothing in this setup, or any setup, eliminates hallucination. The aim is getting 80–90% of the way there, reliably, repeatably. That is massive. If agents can meaningfully contribute to architecture, review, validation, and diagnosis across the full development lifecycle, not just write code, the leverage is real.
But the ceiling is real too, and the triple hallucination reveals its shape. It is not a ceiling of capability — the agents can grep, trace, and verify. It is a ceiling of initiative. They do not spontaneously doubt their own reasoning. They do not say “I should check before I claim.” They answer the question as asked, with the most probable answer they can construct.
The human’s role in the loop is not knowing more. It is the willingness to say “show me” — and the judgement to know when that question needs asking.
The specific topology I have described will evolve. The tools will change. But the observation underneath is structural: cognitive diversity across models is not the same as methodological diversity across tasks. The second matters more than the first for catching the failures that matter. If you are not experimenting with agents across the full development lifecycle, you are leaving capacity on the table. The specific setup matters less than the act of trying, observing what breaks, and iterating. This version works for me now. Yours will look different. That is the point.
[1] Adam Resnick, “How Do Software Developers Spend Their Time?”, IDC Survey Spotlight, February 2025.
[2] Software.com, “Code Time Report”, based on telemetry from 250,000+ developers, 2021.
[3] Ylli Prifti, “The New Units of Economics in Software Engineering”, Weighted Thoughts, 2026.